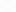客服微信

作者:潘峰
【前言】
大家众所周知TDSQL for mysql 是一款分布式数据库,它最大支持256个分片默认为64个分片。那TDSQL里面的分片概念其实就是所谓的set,当我们使用默认配置创建一个groupshard实例的时候,TDSQL首先会创建一个set在这个set里面会有64个分区。当这个set的性能或者是容量达到一个值的时候,这个时候就可以通过动态扩容的方式添加一个新set来拆分原来的数据。那大家想不想知道TDSQL的动态扩容的逻辑流程呢?它是什么原理呢?下面带大家来揭秘一下。
一
环境介绍
此次我们实验的TDSQL环境为
数据库采用一主两从的结构

二
扩容流程的猜测
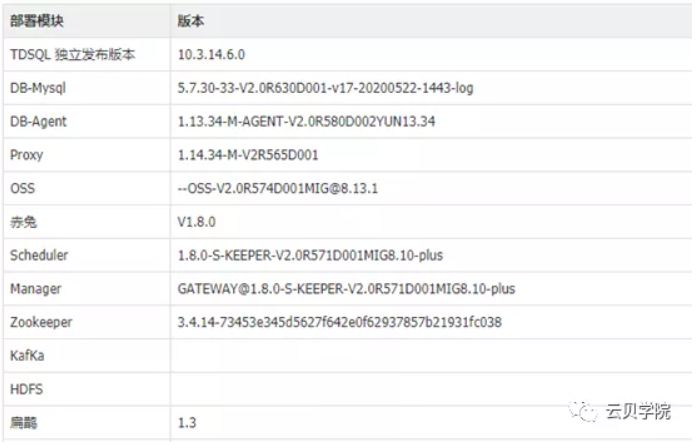
上图是腾讯官方给出的TDSQL执行任务的一个数据流,那么我们可以通过这个流程图来猜测一下TDSQL的groupshard的扩容的一个流程。
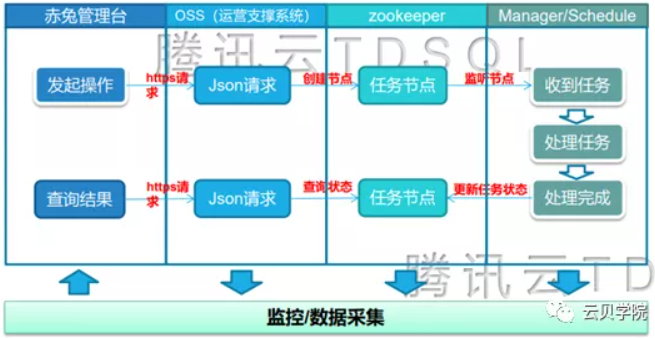
以上流程图是我猜想的一个流程图
首先,赤兔页面设置配置cpu、内存、磁盘信息、主机组信息之后点击提交按钮,然后赤兔平台会把这些参数转化成json串的形式调用oss的接口,接口收到信息之后会在zk上创建一个job节点并把json内容添加到job内容当中。Scheduler watch到节点的变化之后开始执行创建操作(查找硬件资源、初始化数据库、初始化mysqlagent……),当set初始化完成之后会创建出一个一主两从新的空的set。之后利用xtrabackup工具在原set的备份节点上拉一份全备过来,并且每个节点分别开始恢复数据,恢复完成之后与原set的读写节点搭建一个主从的结构同步增量数据,当延迟小于3秒之后打开原set的readonly并锁定路由,scheduler会发起断开新set复制stop slave的命令,之后新旧set 打开读写 解锁路由然后各自删除set内多余的partition。
三
解析TDSQL扩容的逻辑流程
要想解析groupshard添加set的逻辑流程主要有两个方法:
第一种查看源码:由于本人不会java语言所以此种方法放弃。
第二种查看日志:通过各大组件的日志去分析解析TDSQL的扩容流程,以下的分析主要是使用此种方法。
3.1、定位扩容时间点
我们通过TDSQL监控库TDSQLpcloud_monitor里面的t_ossjob来定位扩容job发起的时间点如下图:(fjob_id可以通过赤兔管理台oss任务流程里面获取)
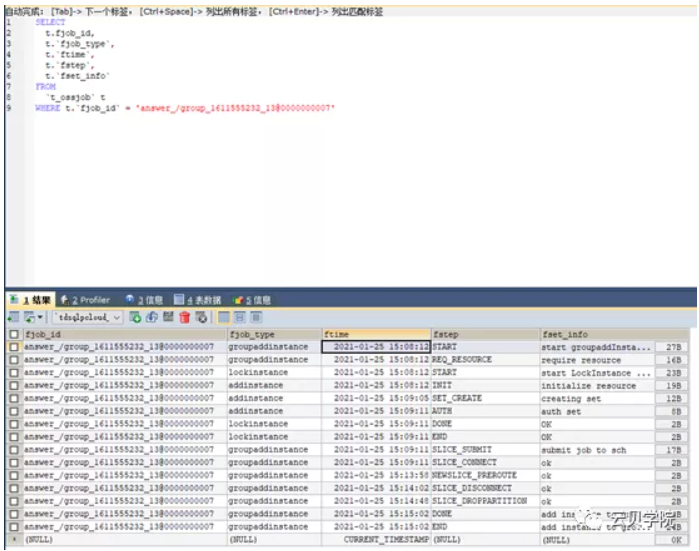
通过查询我们可以得知job发起的时间点是2021-01-25 15:08:12,通过这个时间点我们可以去oss日志里面定位如下图:
日志位置:/data/application/oss/log/sys_TDSQL_oss_log.xxxxx
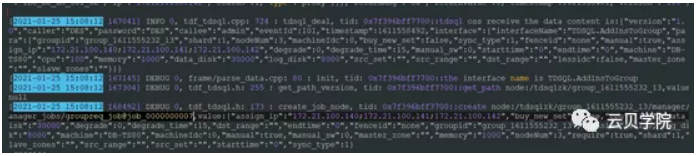
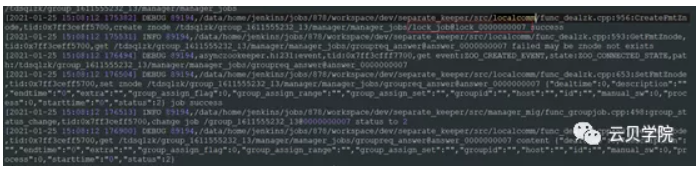
从日志我们可以看到2021-01-25 15:08:12 OSS接收到了一个json数据并调用了TDSQL.ADDInsToGroup这个接口,并且create note:/TDSQLzk/group_1611555232_13/manager/manager_jobs/groupreq_job并赋值
3.2 Zookeeper znode name的横向对比查找
如下图oss日志:创建job groupreq_job@job_000000007并赋值

Scheduler日志:查找groupreq_job@job_000000007

3.3 关键词过滤法
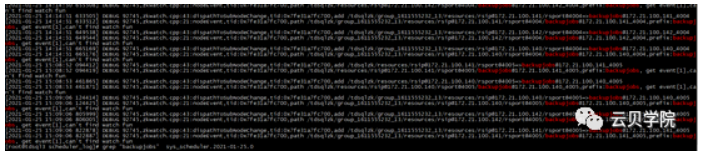
想确认一条日志的是否跟扩容有关,还是常规的检查内容可以通过grep 关键字,过滤日志来判断。
grep backupjobs /data/application/oss/log/ sys_TDSQL_oss_log.xxxxx > grep.log
四
需要分析的日志位置
Oss日志
/data/application/oss/log/sys_tdsql_oss_log.2021-01-25.0Scheduler日志
赤兔确认主节点ip

/data/application/oss/log/sys_scheduler.2021-01-25.0Manager日志

/data/application/oss/log/sys_manager.2021-01-25.0Mysql agent
/data/tdsql_run/4004/mysqlagent/log/ sys_report_4004.log.2021-01-25.0/data/tdsql_run/4005/mysqlagent/log/nohup/xxx.log
五
几个关键点的截图
Oss接收数据->调用接口->创建znode
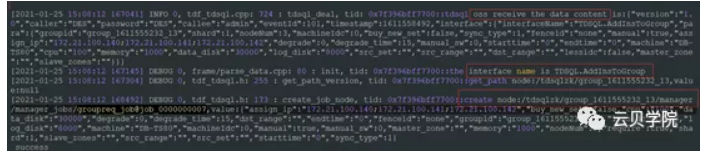
Manager zk watch groupreq_job@job_0000000007拿到数据开始创建set并插入到数据库一条记录
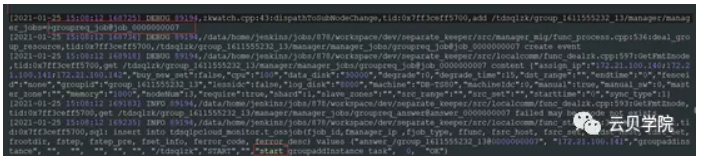
TDSQL pcloud_monitor里面的t_ossjob查询

Manager 完成资源锁定lock_job@lock_0000000007 success
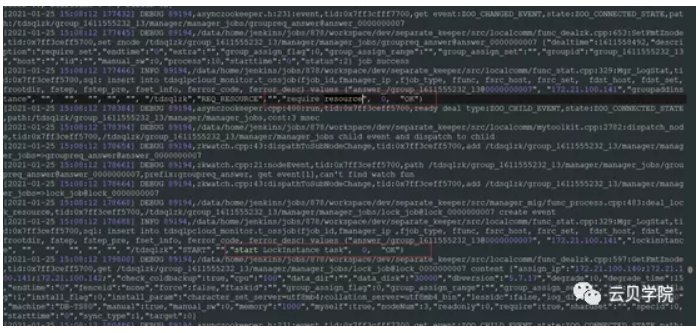
扫描服务器资源记录状态到数据库requireresource资源调配完成锁住资源并记录状态到数据库startlockinstance
Manager 调用shell进行初始化调用install_single_TDSQL_noproxy.sh脚本初始化实例
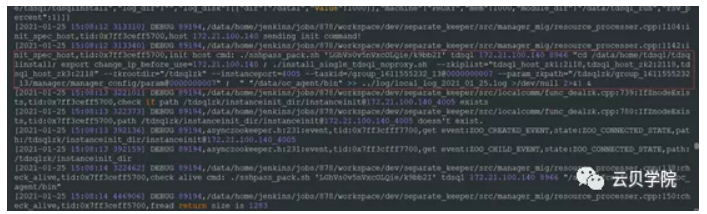
Manger 重启set节点调用Restartreport_cgroup.sh

Manger 创建set完成记录set_create状态到数据库中

Manger创建用户信息TDSQL会创建一个超级用户TDSQLsys_normal
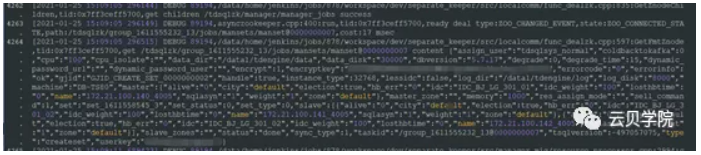
用户创建完成创建完成之后插入数据库一条日志记录authset
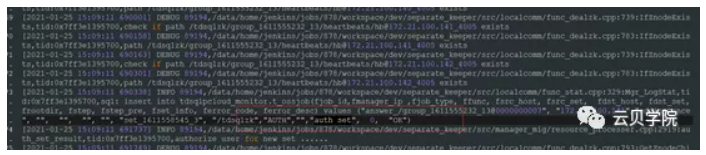
Manager 创建完成set之后把任务转交给scheduler插入数据库一条日志slice_submit

Manager 提交scheduler之后几分钟无日志输出证明任务已经交给scheduler
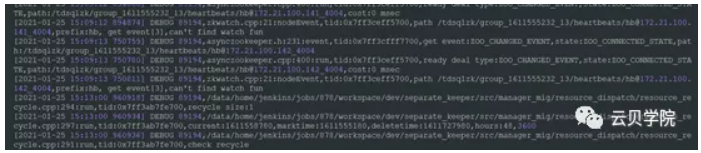
Scheduler与老set 开始主从搭建Set znode信息包括gjid:GJID_NEW_SLICEJOB_00000000014Master_set:set_1611555290_1: set_1611558545¬_3

Mysql agent 与 旧set的一个slave主从搭建使用命令change master to maseter_host=’’ master_port= master_user=’TDSQLsys_repl’ master_password=’’ master_auto_position=1 for channel ‘transfer_set_1611555290_1’

由于新set是一个空库因此需要做数据恢复
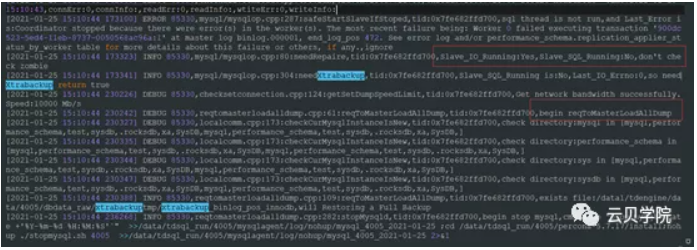
旧set 的备份节点mysqlagent日志开始备份
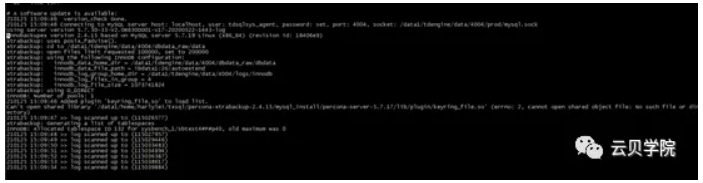
新set apply log 日志
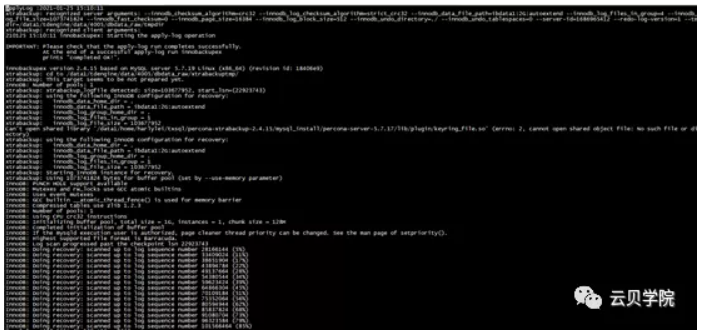
Move datafile日志
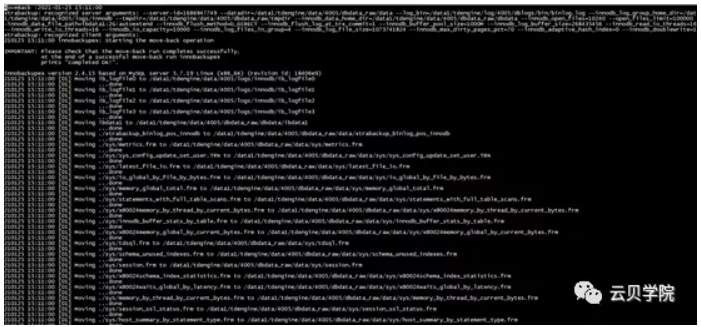
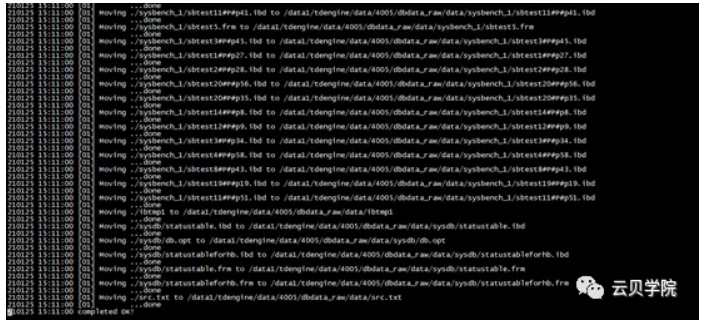
第三节点完成恢复时间
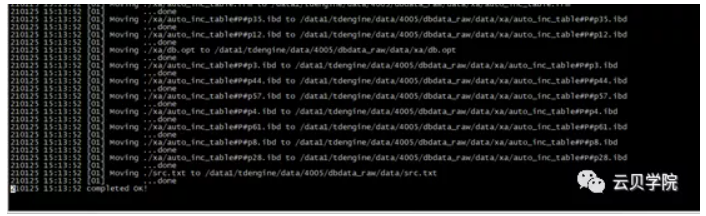
第一节点恢复完成之后立刻与旧set 的salve分片重新搭建主从

Scheduler 准备连接set 拿路由锁
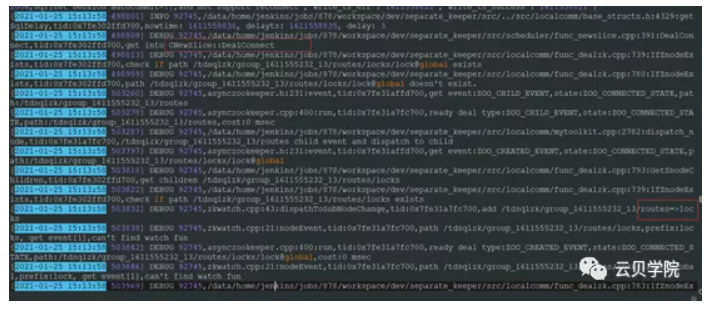
获取第一个set的分片信息
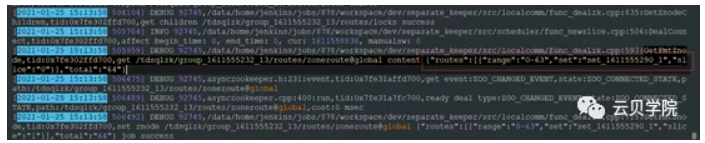
Set znode 主从关系信息

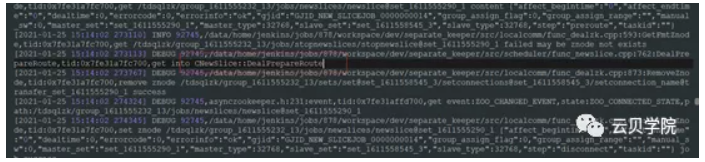
旧set mysql agent 只读读写库并且kill除agent 与 复制的用户
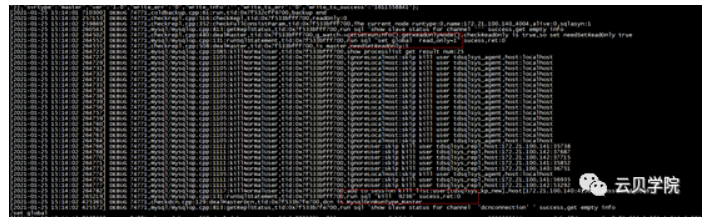
断开主从关系

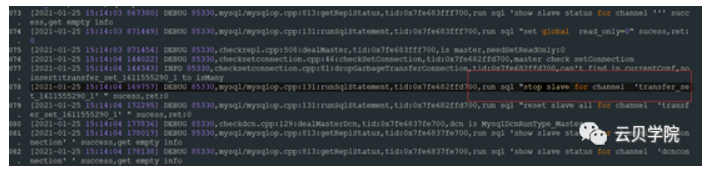
新set 节点Mysql agentStop slave 断开主从关系
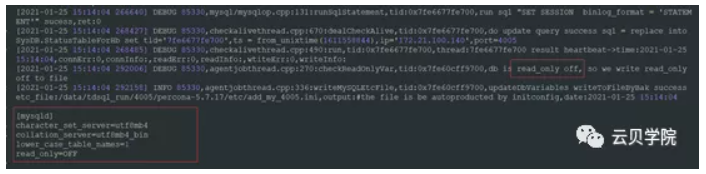
新set 节点Mysql agent 打开只读 写配置文件Read_only off
Scheduler 部署慢查询工具

从14:02-15:48 这段时间我查日志没有发现有太明显的操作,这块还要继续分析

Scheduler切换路由
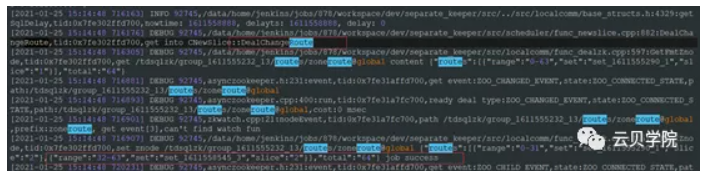
旧set mysql agent打开只读
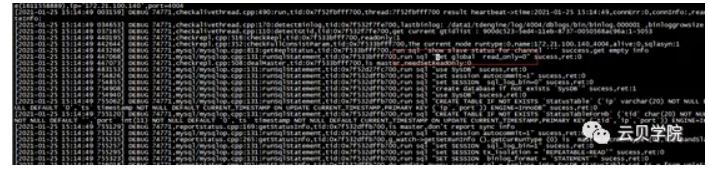
新旧set 同时Drop partition
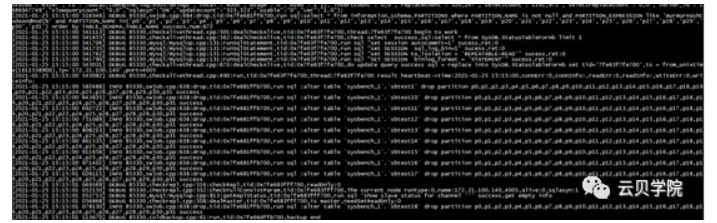
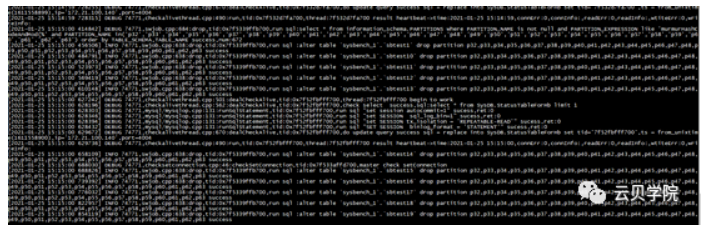
删除lock 扩容完成

总结
通过上面的日志分析我们可以得出以下的结论:1、oss接受赤兔数据并且转成json格式发送zk2、zookeeper接受到数据之后create znode3、manager zk watch后开始锁定物理资源4、manager开始调用脚本install_single_TDSQL_noproxy.sh初始化3个实例5、manager调用Restartreport_cgroup.sh重启实例初始化完成6、manager创建系统用户复制用户7、scheduler创建分片job、GJID_NEW_SLICEJOB_00000000014并确认主从分片信息8、新set mysql agent 与旧set的slave 搭建主从关系9、旧set备份节点做物理备份10、新set三个节点恢复物理备份11、新set的读写节点与旧set的slave做增量同步12、scheduler在新set的延迟小于3秒之后准备断开主从关系13、scheduler拿路由锁和分片信息,旧set readonly,kill除agent与复制用户之外的session14、新set mysql agent 断开只读关系 stop slave15、新节点打开只读写配置文件16、scheduler切换路由17、scheduler部署慢查询工具18、mysql agent 开始删除各set多余的分区(此处有一个流量的控制根据服务器跟数据库的负载)