客服微信

本文为云贝教育 刘峰 原创,请尊重知识产权,转发请注明出处,不接受任何抄袭、演绎和未经注明出处的转载。
在数据库技术的殿堂中,PostgreSQL(简称PG)以其开源、高效、稳定、功能丰富著称誉满载誉全球。在PG的众多特性中,窗函数(Window Functions)是SQL的明珠,为数据分析与处理提供了无与强大的武器。本文将深入浅出PG中的窗函数,引领您探索其精妙用法,解锁数据分析的新天地。
窗函数,顾名思义,是在数据集上定义的一个“窗口”上执行的函数。不同于常规聚合函数对数据整体操作,窗函数可以在每行保持个体性的同时,考虑行间关系,实现动态地计算。这使得在分组排名、滚动统计、区间分析、移动平均等领域尤为得心应手。
引用官方文档的说明

窗口函数调用表示对查询选择的行的某些部分应用类似聚合的函数。与非窗口聚合调用不同,这并不涉及将所选行分组为单个输出行 - 每行在查询输出中保持独立。但是,根据窗口函数调用的分组规范(PARTITION BY 列表),窗口函数可以访问属于当前行组的所有行。窗口函数调用的语法是以下之一:

其中 window_definition 的语法如下

可选的frame_clause可以是以下之一

其中frame_start和frame_end可以是其中之一

和frame_exclusion 可以是其中之一

以下示例在测试环境中运行,请勿在生产环境运行。
postgres=# select * from t2; id | name | subject | score ----+---------+---------+------- 1 | math | AA1 | 0 2 | math | AA2 | 61 3 | math | AA3 | 61 4 | math | AA4 | 81 5 | math | AA5 | 88 6 | math | AA6 | 31 7 | math | AA7 | 51 8 | math | AA8 | 2 9 | math | AA9 | 39 10 | math | AA10 | 95 11 | english | AA1 | 4 12 | english | AA2 | 84 13 | english | AA3 | 33 14 | english | AA4 | 60 15 | english | AA5 | 61 16 | english | AA6 | 20 17 | english | AA7 | 41 18 | english | AA8 | 44 19 | english | AA9 | 46 20 | english | AA10 | 2 21 | article | AA1 | 1 22 | article | AA2 | 63 23 | article | AA3 | 68 24 | article | AA4 | 33 25 | article | AA5 | 55 26 | article | AA6 | 93 27 | article | AA7 | 72 28 | article | AA8 | 59 29 | article | AA9 | 15 30 | article | AA10 | 82 31 | sport | AA1 | 25 32 | sport | AA2 | 38 33 | sport | AA3 | 52 34 | sport | AA4 | 30 35 | sport | AA5 | 25 36 | sport | AA6 | 33 37 | sport | AA7 | 9 38 | sport | AA8 | 81 39 | sport | AA9 | 49 40 | sport | AA10 | 82 (40 rows)
select row_number() over (PARTITION BY subject order by score),* from t2 ;
row_number | id | subject | name | score
------------+----+---------+------+-------
1 | 26 | article | AA6 | 0
2 | 27 | article | AA7 | 7
3 | 28 | article | AA8 | 13
4 | 25 | article | AA5 | 26
5 | 24 | article | AA4 | 30
6 | 21 | article | AA1 | 45
7 | 30 | article | AA10 | 45
8 | 22 | article | AA2 | 55
9 | 29 | article | AA9 | 69
10 | 23 | article | AA3 | 97
1 | 14 | english | AA4 | 0
2 | 13 | english | AA3 | 4
3 | 18 | english | AA8 | 7
4 | 20 | english | AA10 | 38
5 | 15 | english | AA5 | 38
6 | 16 | english | AA6 | 41
7 | 12 | english | AA2 | 56
8 | 17 | english | AA7 | 70
9 | 11 | english | AA1 | 74
10 | 19 | english | AA9 | 77
1 | 1 | math | AA1 | 10
2 | 8 | math | AA8 | 19
3 | 4 | math | AA4 | 29
4 | 7 | math | AA7 | 36
5 | 5 | math | AA5 | 52
6 | 6 | math | AA6 | 68
7 | 9 | math | AA9 | 71
8 | 3 | math | AA3 | 72
9 | 10 | math | AA10 | 75
10 | 2 | math | AA2 | 89
1 | 39 | sport | AA9 | 6
2 | 31 | sport | AA1 | 19
3 | 33 | sport | AA3 | 25
4 | 36 | sport | AA6 | 28
5 | 34 | sport | AA4 | 32
6 | 37 | sport | AA7 | 33
7 | 38 | sport | AA8 | 50
8 | 35 | sport | AA5 | 62
9 | 40 | sport | AA10 | 73
10 | 32 | sport | AA2 | 81
(40 rows)
postgres=# select subject,name,score,avg(score) over(PARTITION BY subject) from t2; subject | name | score | avg ---------+------+-------+--------------------- article | AA1 | 45 | 38.7000000000000000 article | AA2 | 55 | 38.7000000000000000 article | AA3 | 97 | 38.7000000000000000 article | AA4 | 30 | 38.7000000000000000 article | AA5 | 26 | 38.7000000000000000 article | AA6 | 0 | 38.7000000000000000 article | AA7 | 7 | 38.7000000000000000 article | AA8 | 13 | 38.7000000000000000 article | AA9 | 69 | 38.7000000000000000 article | AA10 | 45 | 38.7000000000000000 english | AA1 | 74 | 40.5000000000000000 english | AA2 | 56 | 40.5000000000000000 english | AA3 | 4 | 40.5000000000000000 english | AA4 | 0 | 40.5000000000000000 english | AA5 | 38 | 40.5000000000000000 english | AA6 | 41 | 40.5000000000000000 english | AA7 | 70 | 40.5000000000000000 english | AA8 | 7 | 40.5000000000000000 english | AA9 | 77 | 40.5000000000000000 english | AA10 | 38 | 40.5000000000000000 math | AA1 | 10 | 52.1000000000000000 math | AA2 | 89 | 52.1000000000000000 math | AA3 | 72 | 52.1000000000000000 math | AA4 | 29 | 52.1000000000000000 math | AA5 | 52 | 52.1000000000000000 math | AA6 | 68 | 52.1000000000000000 math | AA7 | 36 | 52.1000000000000000 math | AA8 | 19 | 52.1000000000000000 math | AA9 | 71 | 52.1000000000000000 math | AA10 | 75 | 52.1000000000000000 sport | AA1 | 19 | 40.9000000000000000 sport | AA2 | 81 | 40.9000000000000000 sport | AA3 | 25 | 40.9000000000000000 sport | AA4 | 32 | 40.9000000000000000 sport | AA5 | 62 | 40.9000000000000000 sport | AA6 | 28 | 40.9000000000000000 sport | AA7 | 33 | 40.9000000000000000 sport | AA8 | 50 | 40.9000000000000000 sport | AA9 | 6 | 40.9000000000000000 sport | AA10 | 73 | 40.9000000000000000 (40 rows)
dense_rank()与rank()相反
postgres=# select rank() over (PARTITION BY subject order by score),* from t2 ;
rank | id | subject | name | score
------+----+---------+------+-------
1 | 26 | article | AA6 | 0
2 | 27 | article | AA7 | 7
3 | 28 | article | AA8 | 13
4 | 25 | article | AA5 | 26
5 | 24 | article | AA4 | 30
6 | 21 | article | AA1 | 45 #--成绩一样的场景
6 | 30 | article | AA10 | 45 #--成绩一样的场景
8 | 22 | article | AA2 | 55
9 | 29 | article | AA9 | 69
10 | 23 | article | AA3 | 97
1 | 14 | english | AA4 | 0
2 | 13 | english | AA3 | 4
3 | 18 | english | AA8 | 7
4 | 20 | english | AA10 | 38
4 | 15 | english | AA5 | 38
6 | 16 | english | AA6 | 41
7 | 12 | english | AA2 | 56
8 | 17 | english | AA7 | 70
9 | 11 | english | AA1 | 74
10 | 19 | english | AA9 | 77
1 | 1 | math | AA1 | 10
2 | 8 | math | AA8 | 19
3 | 4 | math | AA4 | 29
4 | 7 | math | AA7 | 36
5 | 5 | math | AA5 | 52
6 | 6 | math | AA6 | 68
7 | 9 | math | AA9 | 71
8 | 3 | math | AA3 | 72
9 | 10 | math | AA10 | 75
10 | 2 | math | AA2 | 89
1 | 39 | sport | AA9 | 6
2 | 31 | sport | AA1 | 19
3 | 33 | sport | AA3 | 25
4 | 36 | sport | AA6 | 28
5 | 34 | sport | AA4 | 32
6 | 37 | sport | AA7 | 33
7 | 38 | sport | AA8 | 50
8 | 35 | sport | AA5 | 62
9 | 40 | sport | AA10 | 73
10 | 32 | sport | AA2 | 81
(40 rows)
postgres=# select lag(id,1) over (),* from t2 ;
lag | id | subject | name | score
-----+----+---------+------+-------
| 1 | math | AA1 | 10
1 | 2 | math | AA2 | 89
2 | 3 | math | AA3 | 72
3 | 4 | math | AA4 | 29
4 | 5 | math | AA5 | 52
5 | 6 | math | AA6 | 68
6 | 7 | math | AA7 | 36
7 | 8 | math | AA8 | 19
8 | 9 | math | AA9 | 71
9 | 10 | math | AA10 | 75
10 | 11 | english | AA1 | 74
11 | 12 | english | AA2 | 56
12 | 13 | english | AA3 | 4
13 | 14 | english | AA4 | 0
14 | 15 | english | AA5 | 38
15 | 16 | english | AA6 | 41
16 | 17 | english | AA7 | 70
17 | 18 | english | AA8 | 7
18 | 19 | english | AA9 | 77
19 | 20 | english | AA10 | 38
20 | 21 | article | AA1 | 45
21 | 22 | article | AA2 | 55
22 | 23 | article | AA3 | 97
23 | 24 | article | AA4 | 30
24 | 25 | article | AA5 | 26
25 | 26 | article | AA6 | 0
26 | 27 | article | AA7 | 7
27 | 28 | article | AA8 | 13
28 | 29 | article | AA9 | 69
29 | 30 | article | AA10 | 45
30 | 31 | sport | AA1 | 19
31 | 32 | sport | AA2 | 81
32 | 33 | sport | AA3 | 25
33 | 34 | sport | AA4 | 32
34 | 35 | sport | AA5 | 62
35 | 36 | sport | AA6 | 28
36 | 37 | sport | AA7 | 33
37 | 38 | sport | AA8 | 50
38 | 39 | sport | AA9 | 6
39 | 40 | sport | AA10 | 73
(40 rows)
这里分组的第一个值由是否使用order by 决定
postgres=# select first_value(score) over (PARTITION BY subject ),* from t2 ;
first_value | id | subject | name | score
-------------+----+---------+------+-------
45 | 21 | article | AA1 | 45
45 | 22 | article | AA2 | 55
45 | 23 | article | AA3 | 97
45 | 24 | article | AA4 | 30
45 | 25 | article | AA5 | 26
45 | 26 | article | AA6 | 0
45 | 27 | article | AA7 | 7
45 | 28 | article | AA8 | 13
45 | 29 | article | AA9 | 69
45 | 30 | article | AA10 | 45
74 | 11 | english | AA1 | 74
74 | 12 | english | AA2 | 56
74 | 13 | english | AA3 | 4
74 | 14 | english | AA4 | 0
74 | 15 | english | AA5 | 38
74 | 16 | english | AA6 | 41
74 | 17 | english | AA7 | 70
74 | 18 | english | AA8 | 7
74 | 19 | english | AA9 | 77
74 | 20 | english | AA10 | 38
10 | 1 | math | AA1 | 10
10 | 2 | math | AA2 | 89
10 | 3 | math | AA3 | 72
10 | 4 | math | AA4 | 29
10 | 5 | math | AA5 | 52
10 | 6 | math | AA6 | 68
10 | 7 | math | AA7 | 36
10 | 8 | math | AA8 | 19
10 | 9 | math | AA9 | 71
10 | 10 | math | AA10 | 75
19 | 31 | sport | AA1 | 19
19 | 32 | sport | AA2 | 81
19 | 33 | sport | AA3 | 25
19 | 34 | sport | AA4 | 32
19 | 35 | sport | AA5 | 62
19 | 36 | sport | AA6 | 28
19 | 37 | sport | AA7 | 33
19 | 38 | sport | AA8 | 50
19 | 39 | sport | AA9 | 6
19 | 40 | sport | AA10 | 73
(40 rows)
postgres=# select first_value(score) over (PARTITION BY subject order by score desc),* from t2 ;
first_value | id | subject | name | score
-------------+----+---------+------+-------
97 | 23 | article | AA3 | 97
97 | 29 | article | AA9 | 69
97 | 22 | article | AA2 | 55
97 | 30 | article | AA10 | 45
97 | 21 | article | AA1 | 45
97 | 24 | article | AA4 | 30
97 | 25 | article | AA5 | 26
97 | 28 | article | AA8 | 13
97 | 27 | article | AA7 | 7
97 | 26 | article | AA6 | 0
77 | 19 | english | AA9 | 77
77 | 11 | english | AA1 | 74
77 | 17 | english | AA7 | 70
77 | 12 | english | AA2 | 56
77 | 16 | english | AA6 | 41
77 | 15 | english | AA5 | 38
77 | 20 | english | AA10 | 38
77 | 18 | english | AA8 | 7
77 | 13 | english | AA3 | 4
77 | 14 | english | AA4 | 0
89 | 2 | math | AA2 | 89
89 | 10 | math | AA10 | 75
89 | 3 | math | AA3 | 72
89 | 9 | math | AA9 | 71
89 | 6 | math | AA6 | 68
89 | 5 | math | AA5 | 52
89 | 7 | math | AA7 | 36
89 | 4 | math | AA4 | 29
89 | 8 | math | AA8 | 19
89 | 1 | math | AA1 | 10
81 | 32 | sport | AA2 | 81
81 | 40 | sport | AA10 | 73
81 | 35 | sport | AA5 | 62
81 | 38 | sport | AA8 | 50
81 | 37 | sport | AA7 | 33
81 | 34 | sport | AA4 | 32
81 | 36 | sport | AA6 | 28
81 | 33 | sport | AA3 | 25
81 | 31 | sport | AA1 | 19
81 | 39 | sport | AA9 | 6
(40 rows)
last_value()分组最后一个值,与last_value()相反。
3.8 nth_value()查看分组指定值
postgres=# select nth_value(score,3) over (PARTITION BY subject ),* from t2 ;
nth_value | id | subject | name | score
-----------+----+---------+------+-------
97 | 21 | article | AA1 | 45
97 | 22 | article | AA2 | 55
97 | 23 | article | AA3 | 97
97 | 24 | article | AA4 | 30
97 | 25 | article | AA5 | 26
97 | 26 | article | AA6 | 0
97 | 27 | article | AA7 | 7
97 | 28 | article | AA8 | 13
97 | 29 | article | AA9 | 69
97 | 30 | article | AA10 | 45
4 | 11 | english | AA1 | 74
4 | 12 | english | AA2 | 56
4 | 13 | english | AA3 | 4
4 | 14 | english | AA4 | 0
4 | 15 | english | AA5 | 38
4 | 16 | english | AA6 | 41
4 | 17 | english | AA7 | 70
4 | 18 | english | AA8 | 7
4 | 19 | english | AA9 | 77
4 | 20 | english | AA10 | 38
72 | 1 | math | AA1 | 10
72 | 2 | math | AA2 | 89
72 | 3 | math | AA3 | 72
72 | 4 | math | AA4 | 29
72 | 5 | math | AA5 | 52
72 | 6 | math | AA6 | 68
72 | 7 | math | AA7 | 36
72 | 8 | math | AA8 | 19
72 | 9 | math | AA9 | 71
72 | 10 | math | AA10 | 75
25 | 31 | sport | AA1 | 19
25 | 32 | sport | AA2 | 81
25 | 33 | sport | AA3 | 25
25 | 34 | sport | AA4 | 32
25 | 35 | sport | AA5 | 62
25 | 36 | sport | AA6 | 28
25 | 37 | sport | AA7 | 33
25 | 38 | sport | AA8 | 50
25 | 39 | sport | AA9 | 6
25 | 40 | sport | AA10 | 73
(40 rows)
postgres=# select avg(score) over(tmp),sum(score) over(tmp) ,* from t2 window tmp as (PARTITION BY subject);
avg | sum | id | subject | name | score
---------------------+-----+----+---------+------+-------
38.7000000000000000 | 387 | 21 | article | AA1 | 45
38.7000000000000000 | 387 | 22 | article | AA2 | 55
38.7000000000000000 | 387 | 23 | article | AA3 | 97
38.7000000000000000 | 387 | 24 | article | AA4 | 30
38.7000000000000000 | 387 | 25 | article | AA5 | 26
38.7000000000000000 | 387 | 26 | article | AA6 | 0
38.7000000000000000 | 387 | 27 | article | AA7 | 7
38.7000000000000000 | 387 | 28 | article | AA8 | 13
38.7000000000000000 | 387 | 29 | article | AA9 | 69
38.7000000000000000 | 387 | 30 | article | AA10 | 45
40.5000000000000000 | 405 | 11 | english | AA1 | 74
40.5000000000000000 | 405 | 12 | english | AA2 | 56
40.5000000000000000 | 405 | 13 | english | AA3 | 4
40.5000000000000000 | 405 | 14 | english | AA4 | 0
40.5000000000000000 | 405 | 15 | english | AA5 | 38
40.5000000000000000 | 405 | 16 | english | AA6 | 41
40.5000000000000000 | 405 | 17 | english | AA7 | 70
40.5000000000000000 | 405 | 18 | english | AA8 | 7
40.5000000000000000 | 405 | 19 | english | AA9 | 77
40.5000000000000000 | 405 | 20 | english | AA10 | 38
52.1000000000000000 | 521 | 1 | math | AA1 | 10
52.1000000000000000 | 521 | 2 | math | AA2 | 89
52.1000000000000000 | 521 | 3 | math | AA3 | 72
52.1000000000000000 | 521 | 4 | math | AA4 | 29
52.1000000000000000 | 521 | 5 | math | AA5 | 52
52.1000000000000000 | 521 | 6 | math | AA6 | 68
52.1000000000000000 | 521 | 7 | math | AA7 | 36
52.1000000000000000 | 521 | 8 | math | AA8 | 19
52.1000000000000000 | 521 | 9 | math | AA9 | 71
52.1000000000000000 | 521 | 10 | math | AA10 | 75
40.9000000000000000 | 409 | 31 | sport | AA1 | 19
40.9000000000000000 | 409 | 32 | sport | AA2 | 81
40.9000000000000000 | 409 | 33 | sport | AA3 | 25
40.9000000000000000 | 409 | 34 | sport | AA4 | 32
40.9000000000000000 | 409 | 35 | sport | AA5 | 62
40.9000000000000000 | 409 | 36 | sport | AA6 | 28
40.9000000000000000 | 409 | 37 | sport | AA7 | 33
40.9000000000000000 | 409 | 38 | sport | AA8 | 50
40.9000000000000000 | 409 | 39 | sport | AA9 | 6
40.9000000000000000 | 409 | 40 | sport | AA10 | 73
(40 rows)
在SQL优化中,有些表被多次调用的情况下,可以通过窗口函数减少表的扫描次数
例如:查看每科的平均成绩
postgres=# select a.subject,a.name,score,tmp.avgsore from t2 a left join (select b.subject,avg(score) as avgsore from t2 b group by b.subject) tmp on a.subject=tmp.subject order by a.subject; subject | name | score | avgsore ---------+------+-------+--------------------- article | AA1 | 45 | 38.7000000000000000 article | AA2 | 55 | 38.7000000000000000 article | AA3 | 97 | 38.7000000000000000 article | AA4 | 30 | 38.7000000000000000 article | AA5 | 26 | 38.7000000000000000 article | AA6 | 0 | 38.7000000000000000 article | AA7 | 7 | 38.7000000000000000 article | AA8 | 13 | 38.7000000000000000 article | AA9 | 69 | 38.7000000000000000 article | AA10 | 45 | 38.7000000000000000 english | AA1 | 74 | 40.5000000000000000 english | AA2 | 56 | 40.5000000000000000 english | AA3 | 4 | 40.5000000000000000 english | AA4 | 0 | 40.5000000000000000 english | AA5 | 38 | 40.5000000000000000 english | AA6 | 41 | 40.5000000000000000 english | AA7 | 70 | 40.5000000000000000 english | AA8 | 7 | 40.5000000000000000 english | AA9 | 77 | 40.5000000000000000 english | AA10 | 38 | 40.5000000000000000 math | AA1 | 10 | 52.1000000000000000 math | AA2 | 89 | 52.1000000000000000 math | AA3 | 72 | 52.1000000000000000 math | AA4 | 29 | 52.1000000000000000 math | AA5 | 52 | 52.1000000000000000 math | AA6 | 68 | 52.1000000000000000 math | AA7 | 36 | 52.1000000000000000 math | AA8 | 19 | 52.1000000000000000 math | AA9 | 71 | 52.1000000000000000 math | AA10 | 75 | 52.1000000000000000 sport | AA1 | 19 | 40.9000000000000000 sport | AA2 | 81 | 40.9000000000000000 sport | AA3 | 25 | 40.9000000000000000 sport | AA4 | 32 | 40.9000000000000000 sport | AA5 | 62 | 40.9000000000000000 sport | AA6 | 28 | 40.9000000000000000 sport | AA7 | 33 | 40.9000000000000000 sport | AA8 | 50 | 40.9000000000000000 sport | AA9 | 6 | 40.9000000000000000 sport | AA10 | 73 | 40.9000000000000000 (40 rows)
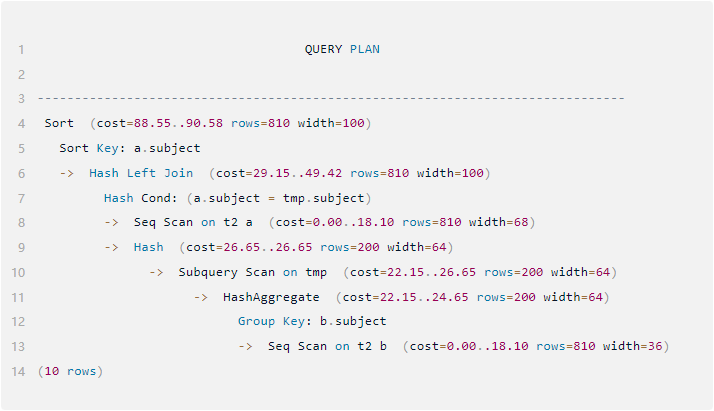
执行计划如下
postgres=# select a.subject,a.name,score,tmp.avgsore from t2 a left join (select b.subject,avg(score) as avgsore from t2 b group by b.subject) tmp on a.subject=tmp.subject order by a.subject; subject | name | score | avgsore ---------+------+-------+--------------------- article | AA1 | 45 | 38.7000000000000000 article | AA2 | 55 | 38.7000000000000000 article | AA3 | 97 | 38.7000000000000000 article | AA4 | 30 | 38.7000000000000000 article | AA5 | 26 | 38.7000000000000000 article | AA6 | 0 | 38.7000000000000000 article | AA7 | 7 | 38.7000000000000000 article | AA8 | 13 | 38.7000000000000000 article | AA9 | 69 | 38.7000000000000000 article | AA10 | 45 | 38.7000000000000000 english | AA1 | 74 | 40.5000000000000000 english | AA2 | 56 | 40.5000000000000000 english | AA3 | 4 | 40.5000000000000000 english | AA4 | 0 | 40.5000000000000000 english | AA5 | 38 | 40.5000000000000000 english | AA6 | 41 | 40.5000000000000000 english | AA7 | 70 | 40.5000000000000000 english | AA8 | 7 | 40.5000000000000000 english | AA9 | 77 | 40.5000000000000000 english | AA10 | 38 | 40.5000000000000000 math | AA1 | 10 | 52.1000000000000000 math | AA2 | 89 | 52.1000000000000000 math | AA3 | 72 | 52.1000000000000000 math | AA4 | 29 | 52.1000000000000000 math | AA5 | 52 | 52.1000000000000000 math | AA6 | 68 | 52.1000000000000000 math | AA7 | 36 | 52.1000000000000000 math | AA8 | 19 | 52.1000000000000000 math | AA9 | 71 | 52.1000000000000000 math | AA10 | 75 | 52.1000000000000000 sport | AA1 | 19 | 40.9000000000000000 sport | AA2 | 81 | 40.9000000000000000 sport | AA3 | 25 | 40.9000000000000000 sport | AA4 | 32 | 40.9000000000000000 sport | AA5 | 62 | 40.9000000000000000 sport | AA6 | 28 | 40.9000000000000000 sport | AA7 | 33 | 40.9000000000000000 sport | AA8 | 50 | 40.9000000000000000 sport | AA9 | 6 | 40.9000000000000000 sport | AA10 | 73 | 40.9000000000000000 (40 rows)
执行计划如下

通过对比两个SQL的语义和结果,可以确认两者等价。但执行计划显示,第一个SQL对T2表扫描两次,而第二个SQL对T2表扫描一次,那必然是T2的执行计划更优。
简而言之,窗口函数极大地扩展了SQL的表达能力,使数据处理更加灵活和精细,特别是在复杂数据分析任务中,它能够直接在数据库层面解决很多原本需要多层迭代或程序逻辑的问题,提高效率并简化数据处理流程。
想了解更多PostgreSQL相关的学习资料(技术文章和视频),可以微信公众号或B站搜索《云贝教育》,免费获取。
想了解更多PostgreSQL相关的学习资料(技术文章和视频),可以微信公众号或B站搜索《云贝教育》,免费获取。
想了解更多PostgreSQL相关的学习资料(技术文章和视频),可以微信公众号或B站搜索《云贝教育》,免费获取。