客服微信

注: 本文为云贝教育 刘峰 原创,请尊重知识产权,转发请注明出处,不接受任何抄袭、演绎和未经注明出处的转载。
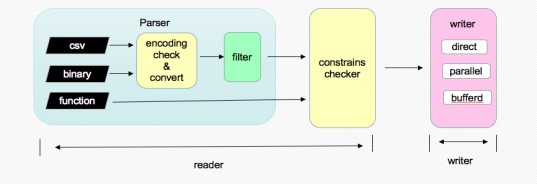
pg_bulkload 是一个高性能的数据加载工具,专门为PostgreSQL数据库设计,用于大批量数据的快速导入
pg_bulkload的工作原理是绕过传统的SQL INSERT语句,通过直接写入底层数据文件和WAL日志,显著提升了数据加载速度和效率。
下面是pg_bulkload的一些核心特性和使用方法:
1.设计理念:
pg_bulkload旨在实现批量数据加载的高性能和高吞吐量,特别适合大数据导入、历史数据迁移和数据分析场景。
2. 工作流程:
控制文件:pg_bulkload通过一个控制文件(control file)来配置导入过程,包括数据源、目标表、字段映射、错误处理策略等。
数据文件:原始数据通常以CSV、TXT或其他格式存储在数据文件中。
日志文件:加载过程中产生的错误记录会写入到错误日志文件中。
并行导入:pg_bulkload可以利用多核处理器并行加载数据,进一步提升导入速度。
3. 主要特性:
快速导入:通过直接写入数据文件和WAL日志而非逐行插入,极大地减少了数据库的IO负担和事务开销。
错误处理:支持错误记录重试、跳过或记录到特定文件,允许在导入过程中灵活处理错误数据。
并行处理:通过多线程和多进程的方式并行加载数据,充分利用硬件资源。
过滤和转换:支持在导入过程中对数据进行简单的过滤和转换操作。
1、创建目标表并初始化插件
psql testdb
testdb=# create table test2 (id int,name text);
CREATE TABLE
testdb=# create extension pg_bulkload; #创建扩展以生成pgbulkload.pg_bulkload() 函数
CREATE EXTENSION
testdb=# \dx
List of installed extensions
Name | Version | Schema | Description
-------------+---------+------------+-----------------------------------------------------------------
pg_bulkload | 3.1.21 | public | pg_bulkload is a high speed data loading utility for PostgreSQL
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(2 rows)
2、准备导入数据
seq 100| awk '{print $0"|test"$0}' >> bulk_test2.txt
3、加载数据到目标表
[postgres@ora19c ~]$ pg_bulkload -i /home/postgres/bulk_test2.txt -O test2 -l /home/postgres/test2.log -P /home/postgres/test2.txt -o "TYPE=CSV" -o "DELIMITER=|" -d testdb -U postgres -h 127.0.0.1
NOTICE: BULK LOAD START
2024-03-24 00:02:14.495 CST [24105] LOG: pg_bulkload: creating missing LSF directory "pg_bulkload"
2024-03-24 00:02:14.495 CST [24105] STATEMENT: SELECT * FROM pgbulkload.pg_bulkload($1)
NOTICE: BULK LOAD END
0 Rows skipped.
100100 Rows successfully loaded.
0 Rows not loaded due to parse errors.
0 Rows not loaded due to duplicate errors.
0 Rows replaced with new rows.
4、查看对应的日志
[postgres@ora19c ~]$ cat /home/postgres/test2.log pg_bulkload 3.1.21 on 2024-03-24 00:02:14.495113+08 INPUT = /home/postgres/bulk_test2.txt PARSE_BADFILE = /home/postgres/test2.txt LOGFILE = /home/postgres/test2.log LIMIT = INFINITE PARSE_ERRORS = 0 CHECK_CONSTRAINTS = NO TYPE = CSV SKIP = 0 DELIMITER = | QUOTE = "\"" ESCAPE = "\"" NULL = OUTPUT = public.test2 MULTI_PROCESS = NO VERBOSE = NO WRITER = DIRECT DUPLICATE_BADFILE = /data/pgdata/data/pg_bulkload/20240324000214_testdb_public_test2.dup.csv DUPLICATE_ERRORS = 0 ON_DUPLICATE_KEEP = NEW TRUNCATE = NO 0 Rows skipped. 100100 Rows successfully loaded. 0 Rows not loaded due to parse errors. 0 Rows not loaded due to duplicate errors. 0 Rows replaced with new rows. Run began on 2024-03-24 00:02:14.495113+08 Run ended on 2024-03-24 00:02:14.634326+08 CPU 0.03s/0.01u sec elapsed 0.14 sec
5、使用控制文件来加载数据
# 新建控制文件 ,可以根据之前加载时,产生的日志文件test2.log来更改,去掉里面没有值的参数 NULL = vi test2.ctl INPUT = /home/postgres/bulk_test2.txt PARSE_BADFILE = /home/postgres/test2r_bad.txt LOGFILE = /home/postgres/test2_output.log LIMIT = INFINITE PARSE_ERRORS = 0 CHECK_CONSTRAINTS = NO TYPE = CSV SKIP = 0 DELIMITER = | QUOTE = "\"" ESCAPE = "\"" OUTPUT = public.test2 MULTI_PROCESS = NO VERBOSE = NO WRITER = DIRECT DUPLICATE_BADFILE = /data/pgdata/data/pg_bulkload/20240324000214_testdb_public_test2.dup.csv DUPLICATE_ERRORS = 0 ON_DUPLICATE_KEEP = NEW TRUNCATE = YES
6、使用控制文件来加载数据
pg_bulkload /home/postgres/test2.ctl -d testdb -U postgres -h 127.0.0.1
NOTICE: BULK LOAD START
NOTICE: BULK LOAD END
0 Rows skipped.
100100 Rows successfully loaded.
0 Rows not loaded due to parse errors.
0 Rows not loaded due to duplicate errors.
0 Rows replaced with new rows.
pg_bulkload 默认是跳过buffer 直接写文件 ,如果写的过程出现异常,需要wal日志恢复时,加载 -o "WRITER=BUFFERED" 参数可以强制让其写wal日志 。
pg_bulkload -i /home/postgres/bulk_test2.txt -O test2 -l /home/postgres/test2.log -P /home/postgres/test2.txt -o "TYPE=CSV" -o "DELIMITER=|" -o "TRUNCATE=YES" -o "WRITER=BUFFERED" -d testdb -U postgres -h 127.0.0.1
那如何证明?其实不难,一是可以跟踪pg_bulkload的函数调用写日志的次数,二是对比加不加参数WRITER=BUFFERED前后日志量
我们先用第二种方法对比日志量
1)不加参数WRITER=BUFFERED
--调用pg_bulkload前 testdb=# select pg_current_wal_lsn(); pg_current_wal_lsn -------------------- 0/2DB5000 (1 row) ----调用pg_bulkload pg_bulkload -i /home/postgres/bulk_test2.txt -O test2 -l /home/postgres/test2.log -P /home/postgres/test2.txt -o "TYPE=CSV" -o "DELIMITER=|" -d testdb -U postgres -h 127.0.0.1 --调用pg_bulkload后 testdb=# select '0/26CAD68'::pg_lsn; pg_lsn ----------- 0/2DB70C0 (1 row)
查看产生的日志量
testdb=# select '0/2DB70C0'::pg_lsn-'0/2DB5000'::pg_lsn;
?column?
----------
8384
2)加参数WRITER=BUFFERED
testdb=# select pg_current_wal_lsn(); pg_current_wal_lsn -------------------- 0/26CAD68 (1 row) pg_bulkload -i /home/postgres/bulk_test2.txt -O test2 -l /home/postgres/test2.log -P /home/postgres/test2.txt -o "TYPE=CSV" -o "DELIMITER=|" -o "TRUNCATE=YES" -o "WRITER=BUFFERED" -d testdb -U postgres -h 127.0.0.1 testdb=# select pg_current_wal_lsn(); pg_current_wal_lsn -------------------- 0/2DB5000 (1 row)
查看产生的日志量
testdb=# select '0/2DB5000'-'0/26CAD68'::pg_lsn::pg_lsn; ?column? ---------- 7250584 (1 row)
由此可见,日志产生量巨大!从侧面也可以验证pg_bulkload默认情况下,只会产生少量的wal日志。
想了解更多PG相关的学习资料(技术文章和视频),可以微信公众号或B站搜索《云贝教育》,免费获取。
想了解更多PG相关的学习资料(技术文章和视频),可以微信公众号或B站搜索《云贝教育》,免费获取。
想了解更多PG相关的学习资料(技术文章和视频),可以微信公众号或B站搜索《云贝教育》,免费获取。
另外需要学习资料 的同学,可以添加联系方式:(同V) 陈老师 199-4146-4235 / 郑老师 199-0663-2509 / 蕾老师199-0663-5786,我们会持续更新学习视频。