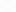客服微信

作者:jasong
原文链接:列存数据库 Code Generation & Vectorized Model-腾讯云开发者社区-腾讯云 (tencent.com)
Push Base Pull Base
很多同学认为,笔者之前也这么认为(才疏学浅)
1. Volcano Model 不能和 向量化兼容
2. Pull Base Model 不能和 向量化兼容
3. Code Generation 技术不能与 向量化兼容
4. 向量化 只能和 PipeLine Mode 兼容
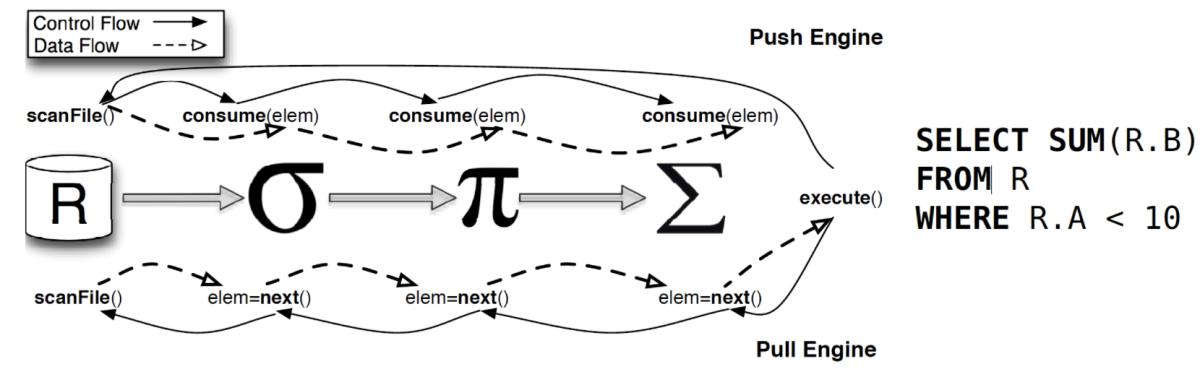
现在个人只是储备来看,向量化跟以上是都可以兼容的,所有引擎是可以简单都理解为是Valcano Model 的变种吧
列存 vs 行存
1. Batter Compresion Ratio
2. Mini IO (Projection Parttion Prunning 、Predicate Push Down/Filter)
之前的误解
1. 个人之前的理解是 Push Engine 是最好的,因为是数据驱动的计算,目前个人理解来看现在的数据库两者都可,没有太大对错
2. 之前的理解为必须实现Push Engine 才能实现深度得向量化引擎,目前个人理解就是 不冲突

1. Push Base Engine == Pipeline Engine
2. Pull Base Engine == Valcano Model 升级吧 这里不是完全正确(我理解目前没有完全好的一个名字替代它 可以叫 Spark SQL Engine)
两级分化,因为Code Generation 和 Vetorized Model 的使用偏重,出现了组合拳,但是很多人理解他们水火不融,个人理解可以为
1. PipeLine Engine == Vectorized Model (主) + Code Generation Model (辅)
2. Spark Engine = Code Generation Model(主) + Vetorizied Model (辅)
PipeLine Engine 是向量化驱动,CodeGen 优化虚函数, Spark Engine 是 CodeGen 驱动, 向量化跟进, 都有向量化的能力,都有Code Genration 的能力
准确应该叫
Spark = Whole-Stage Code Generation + Vectorization
ClickHouse = Vectorization + Runtime Code Generation
Vectorized Model:解决复杂的数据处理逻辑(Function)
Code Generation: 解决简单的上下文切换 (数据装箱、虚函数 多态)
Whole-Stage Code Generation: SQL语句编译后的operator-tree中,每个operator执行时就不是自己来执行逻辑了,而是通过whole-stage code generation技术,动态生成代码
Runtime Code Generation: ClickHouse实现了Expression级别的runtime codegen
PipeLine : ClickHouse 为主 、DuckDB、TiFlash 向量化(不过其加入了MPP)、DataBend、StarRocks 新版、Doris 新版
Valcano Model: Impala 、TiDB、StarRocks 旧版、Doris 旧版、PG、Spark
位置: ADB .... 、Snowflake、DataBricks、Velox